任务投递模式快速开始(推荐)
本节将会以VSCode为例介绍如何通过任务投递模式进行远程开发,完成GPU调用。
插件初始化
插件安装
-
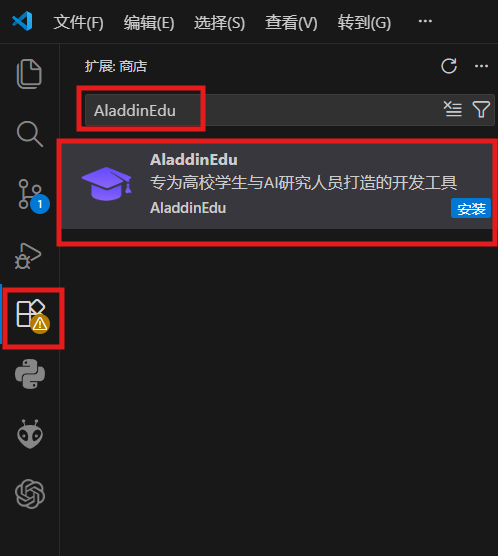
在VSCode扩展中搜索AladdinEdu,点击安装(若在Cursor中使用,需在AladdinEdu官网下载AladdinEdu插件安装包,并将安装包拖至Cursor扩展区内手动安装):
-
安装完成后可在活动栏看到AladdinEdu插件图标,安装成功:
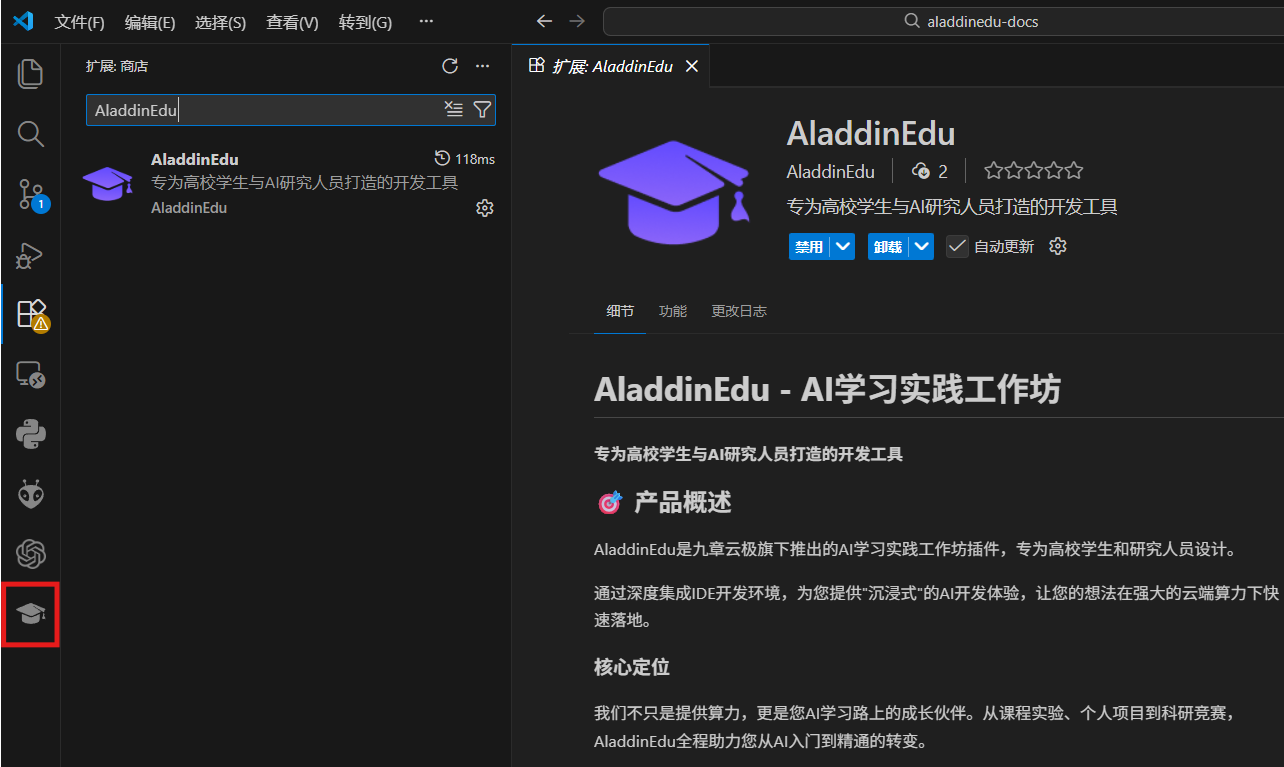
也可在登录AladdinEdu后,在「我的实验室」页面,点击“下载AladdinEdu插件”下载vsix格式的安装包,将安装包拖拽至扩展区即可安装成功。
账号登录
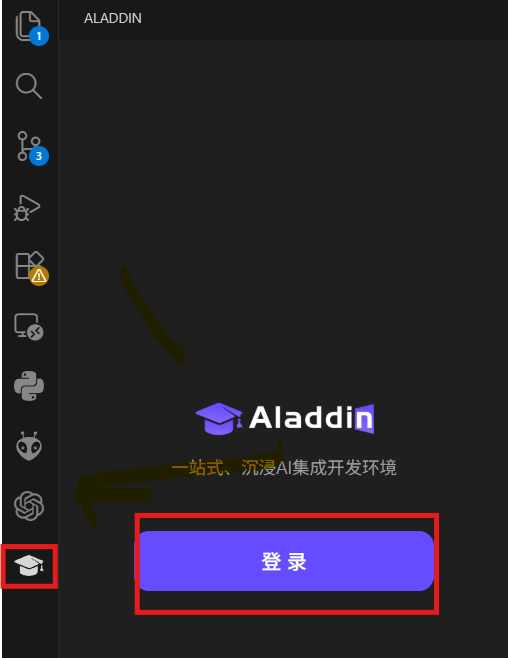
- 点击AladdinEdu插件图标,选择登录,弹窗后选择“打开”外部网站(AladdinEdu平台):
mac用户请注意,不要使用Safari浏览器打开链接,请使用其他浏览器。
-
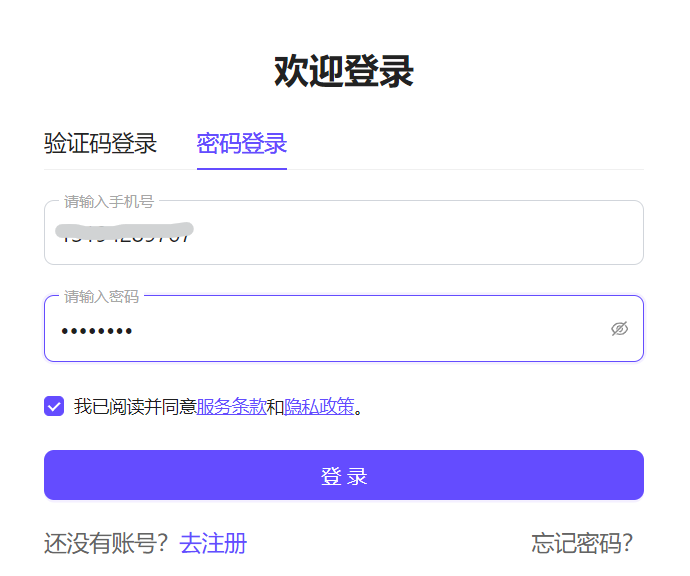
在AladdinEdu平台中使用手机号或账号密码登录,首次使用者请先注册:
-
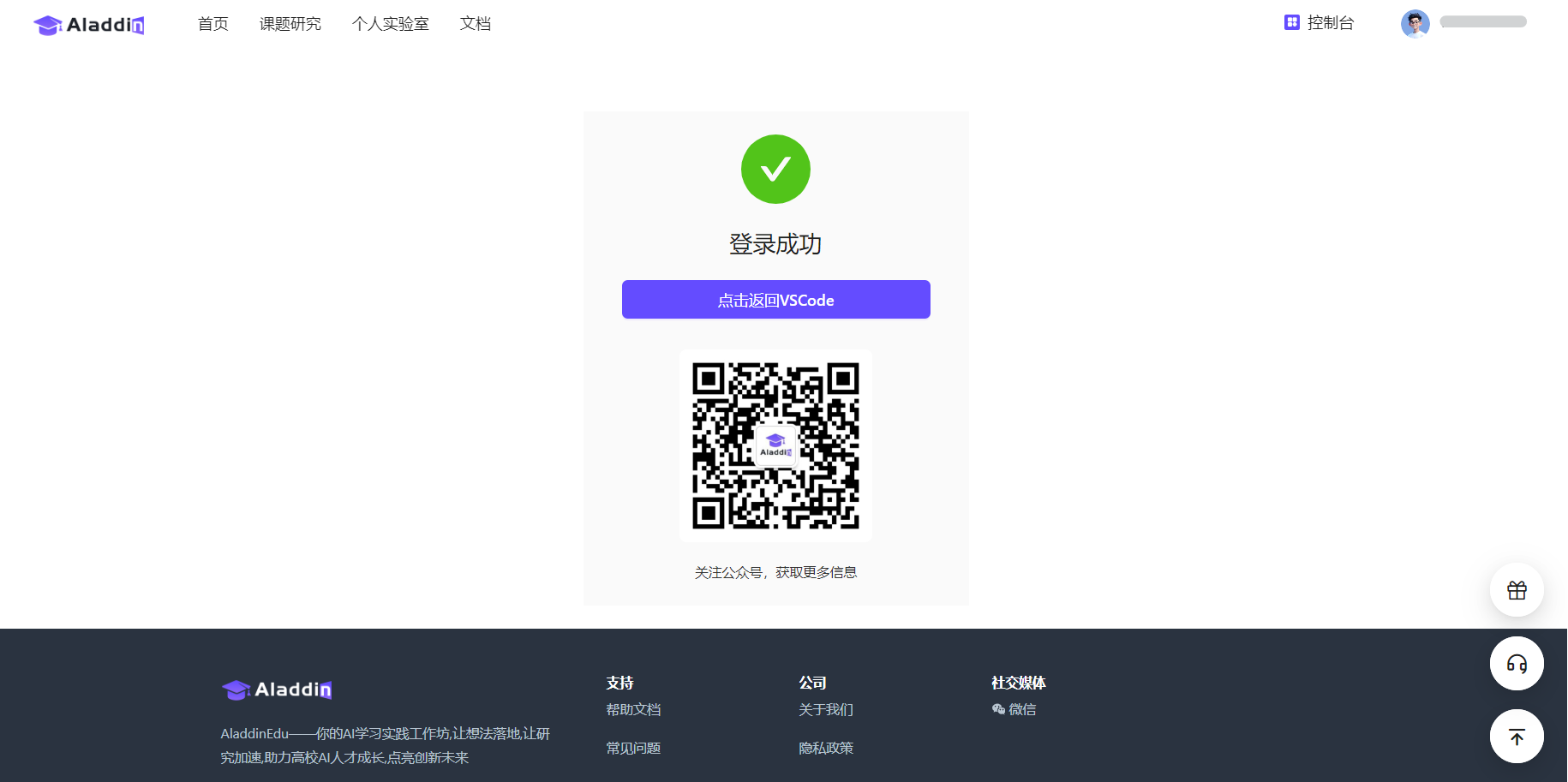
登录成功后点击“点击返回VSCode”,等待返回VSCode(如未自动跳转,请手动返回VSCode)。此时VSCode中出现弹窗,选择“打开”此URL,提示登录成功:

workshop创建
workshop为AladdinEdu插件的远程工作台,可在本地VSCode中连接远程服务器进行开发与调试。
停止workshop时,workshop中 /root下的数据将全部保存,但不包括额外安装的python包,因此重新启动后无需再次上传数据,但需重新安装python包,强烈建议安装python包后保存自定义镜像。
-
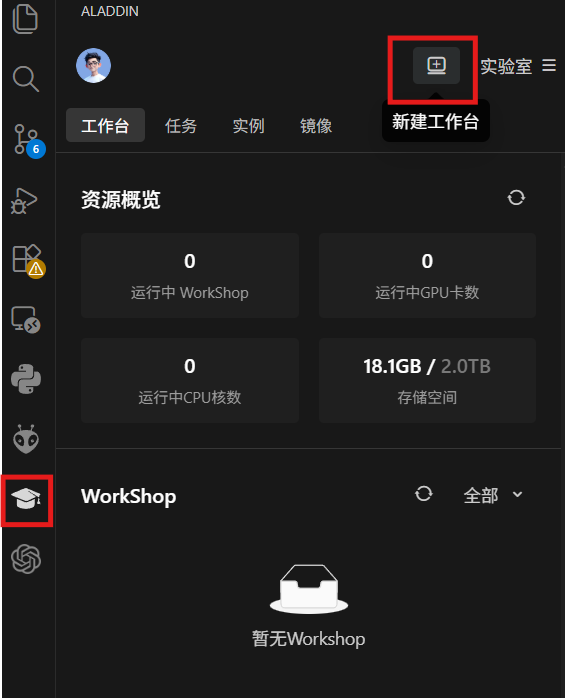
在实验室菜单栏中点击 +,新建工作台:
-
填写工作台名称,选择集群分区,基础镜像与CPU(免费版会员推荐选择“CPU:2 MEM:8G”):
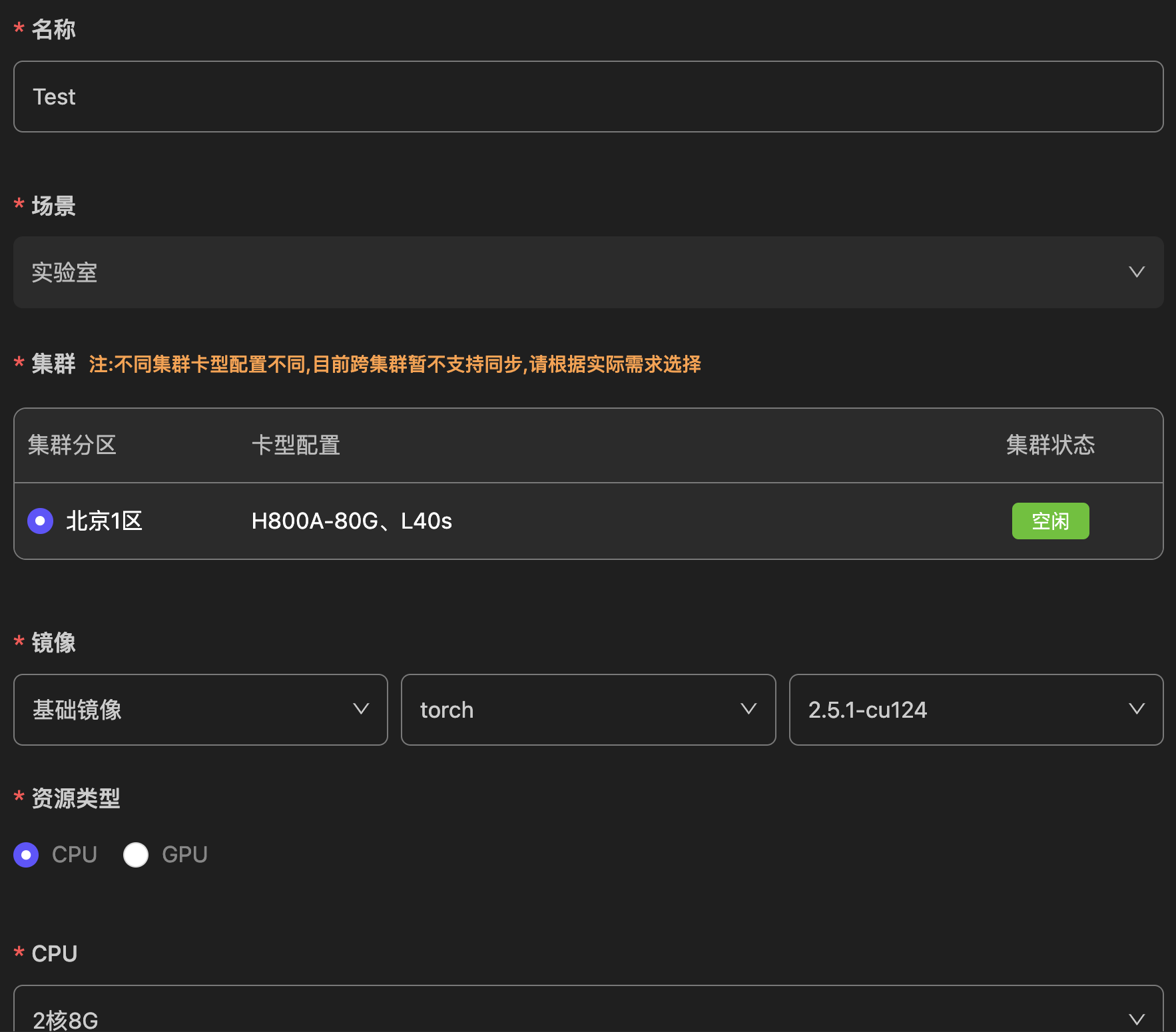
- workshop启动参数介绍
| 参数名称 | 说明 | 备注 |
|---|---|---|
| 镜像 | 当前workshop使用的容器镜像 | 通常包含预装软件和基础运行环境 |
| 资源类型 | 当前workshop启动时分配到的CPU和内存资源 | CPU免费额度与计费方式请参考定价与计费 |
| ENV | 当前workshop运行时的环境变量 | 可用于配置应用参数、API密钥等信息 |
- 镜像介绍可查看环境配置
-
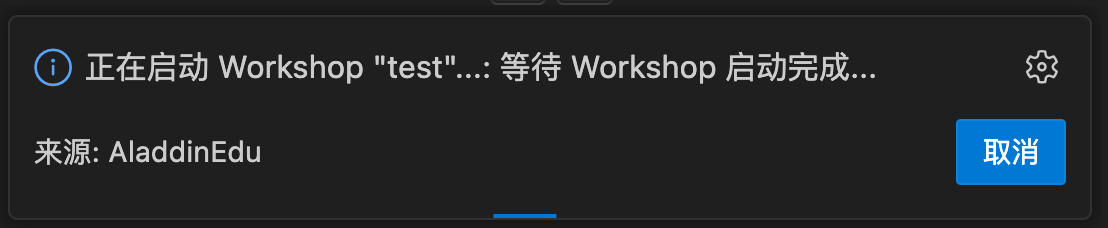
点击提交后会出现插件的状态提示,配置预计在2min左右完成:
-
此时会弹出一个新窗口(后文统称为远端页面),workshop创建完成:
运行Demo
以下操作均在远端页面中进行。
使用镜像运行Demo
在AladdinEdu平台使用镜像时,可先参考平台机制介绍。
-
在/root路径下,新建test.py文件,将测试代码复制到文件中,保存文件:
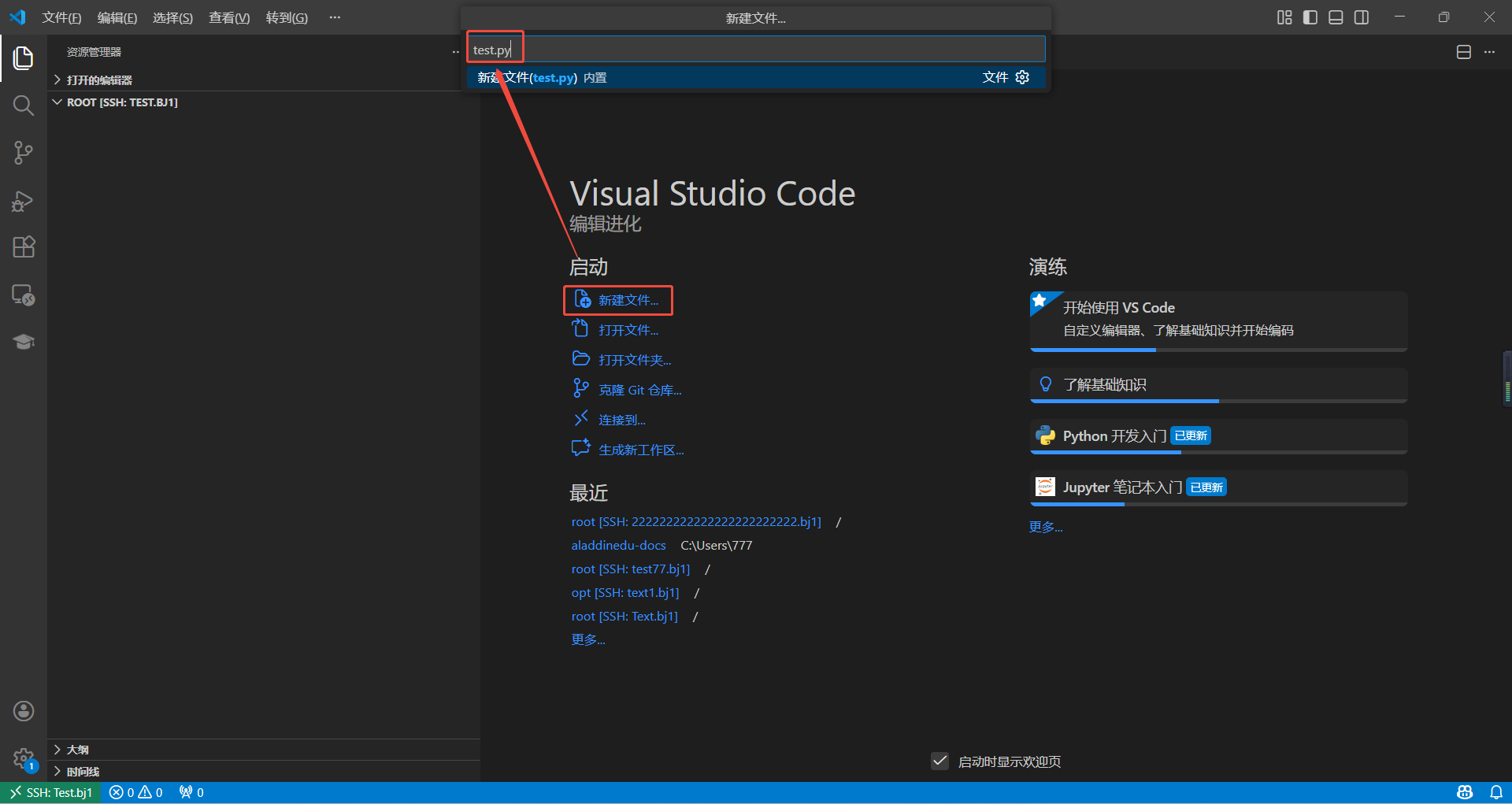
import torch
import time
def test_cuda_availability():
print("\n======= CUDA 测试 =======")
# 检查 CUDA 是否可用
cuda_available = torch.cuda.is_available()
print(f"PyTorch CUDA 可用: {'✅是' if cuda_available else '❌否'}")
if cuda_available:
# 打印 CUDA 版本和设备信息
print(f"PyTorch CUDA 版本: {torch.version.cuda}")
print(f"当前 GPU 设备: {torch.cuda.get_device_name(0)}")
print(f"GPU 数量: {torch.cuda.device_count()}")
else:
print("⚠️ 请检查 CUDA 和 PyTorch 是否安装正确!")
print("========================\n")
def test_gpu_speed():
print("\n======= GPU 速度测试 =======")
# 创建一个大型张量
x = torch.randn(10000, 10000)
# CPU 计算
start_time = time.time()
x_cpu = x * x
cpu_time = time.time() - start_time
print(f"CPU 计算时间: {cpu_time:.4f} 秒")
if torch.cuda.is_available():
# 移动到 GPU 计算
x_gpu = x.to('cuda')
start_time = time.time()
x_gpu = x_gpu * x_gpu
torch.cuda.synchronize() # 确保 GPU 计算完成
gpu_time = time.time() - start_time
print(f"GPU 计算时间: {gpu_time:.4f} 秒")
print(f"GPU 比 CPU 快: {cpu_time / gpu_time:.1f} 倍")
else:
print("⚠️ GPU 不可用,跳过测试")
print("==========================\n")
def test_training():
print("\n======= 简单训练测试 =======")
# 定义一个极简神经网络
model = torch.nn.Sequential(
torch.nn.Linear(10, 100),
torch.nn.ReLU(),
torch.nn.Linear(100, 1)
)
# 如果有 GPU,将模型和数据移到 GPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = model.to(device)
print(f"使用设备: {device.upper()}")
# 模拟数据
X = torch.randn(1000, 10).to(device)
y = torch.randn(1000, 1).to(device)
# 训练循环
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
start_time = time.time()
for epoch in range(5):
optimizer.zero_grad()
output = model(X)
loss = torch.nn.functional.mse_loss(output, y)
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {loss.item():.4f}")
total_time = time.time() - start_time
print(f"总训练时间: {total_time:.2f} 秒")
print("==========================\n")
if __name__ == "__main__":
test_cuda_availability()
test_gpu_speed()
test_training()
-
选择代码首行的“运行”按钮。在创建会话中,镜像需选择为aladdin/pytorch,资源类型为GPU,其余无需修改。点击“提交”:
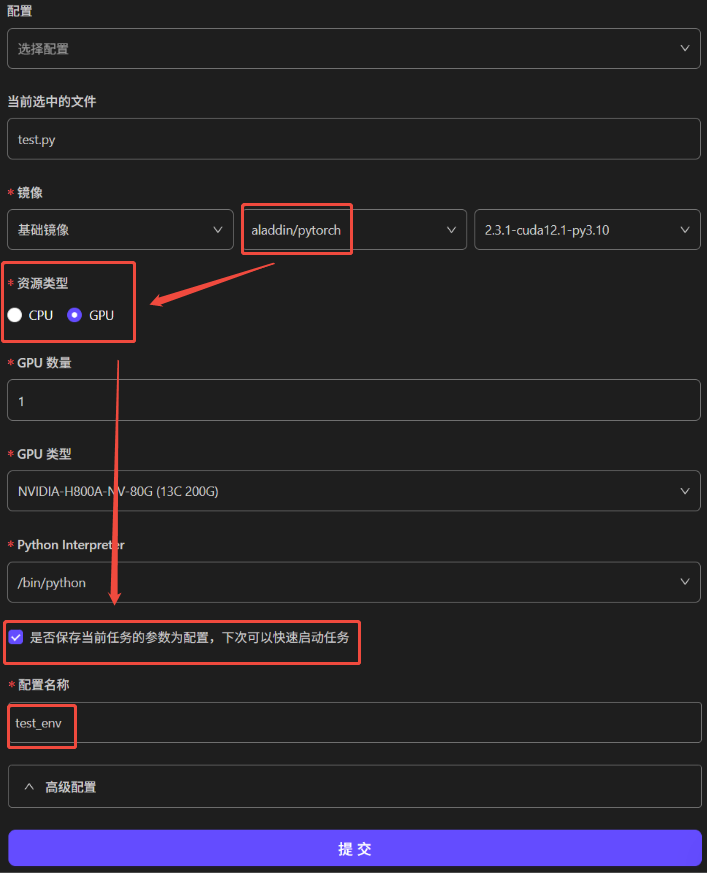
若选择保存当前任务的参数设置,下次可在启动任务时再次使用该配置。

输出内容案例:
======= CUDA 测试 =======
PyTorch CUDA 可用: ✅是
PyTorch CUDA 版本: 12.1
当前 GPU 设备: NVIDIA H100 80GB HBM3
GPU 数量: 1
=========================
======= GPU 速度测试 ======
CPU 计算时间: 0.0116 秒
GPU 计算时间: 0.0070 秒
GPU 比 CPU 快: 1.6 倍
==========================
======= 简单训练测试 =======
使用设备: CUDA
Epoch 1, Loss: 1.0493
Epoch 2, Loss: 1.0266
Epoch 3, Loss: 1.0107
Epoch 4, Loss: 0.9994
Epoch 5, Loss: 0.9914
总训练时间: 0.09 秒
===========================
- 或使用“快速运行”启动GPU会话:
3.1 添加快速启动所需的GPU配置文件,依次点击“运行和调试”、“创建一个 launch.json 文件”、“Aladdin 远程 Python 调试(附加)”:
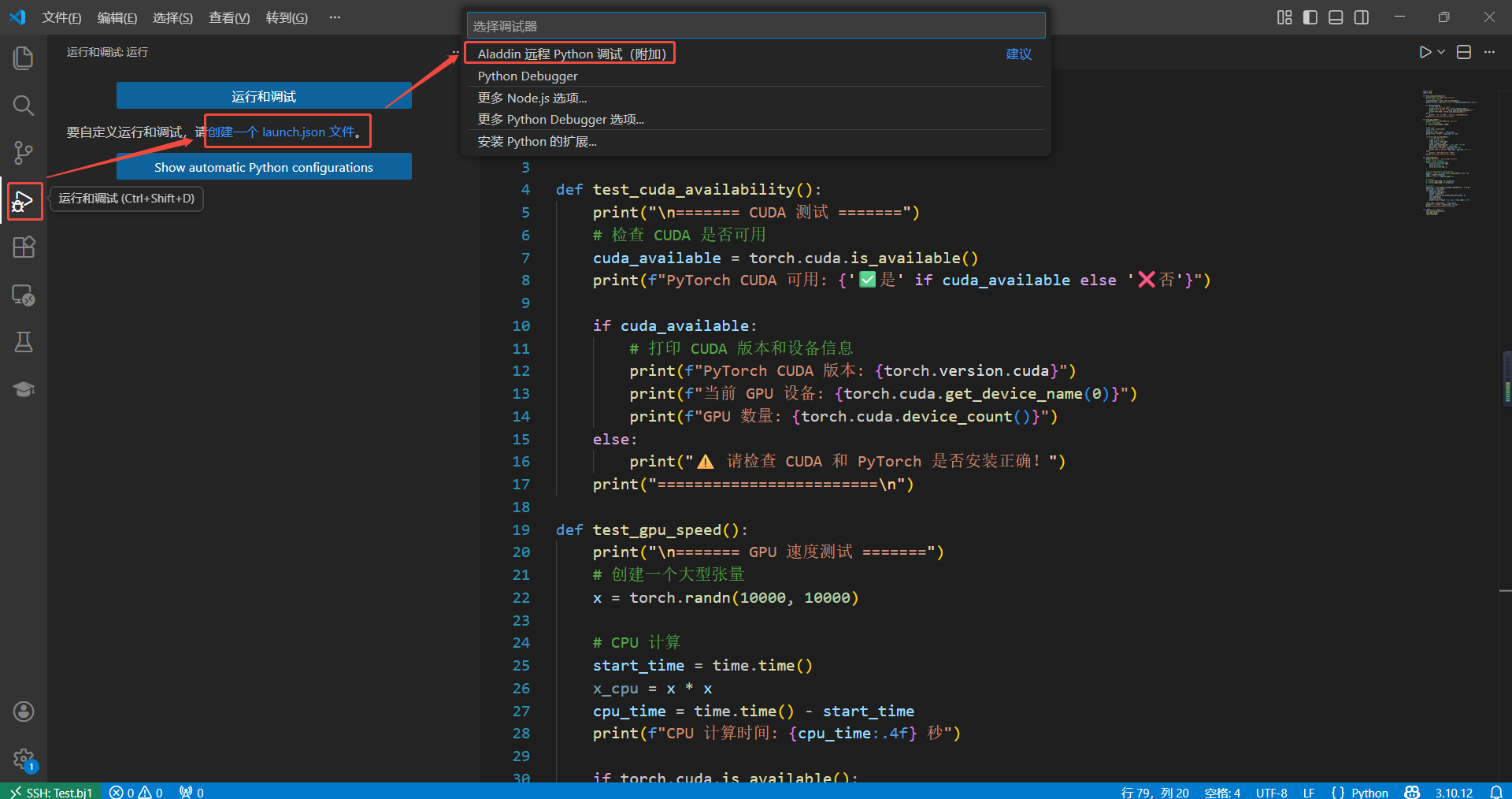
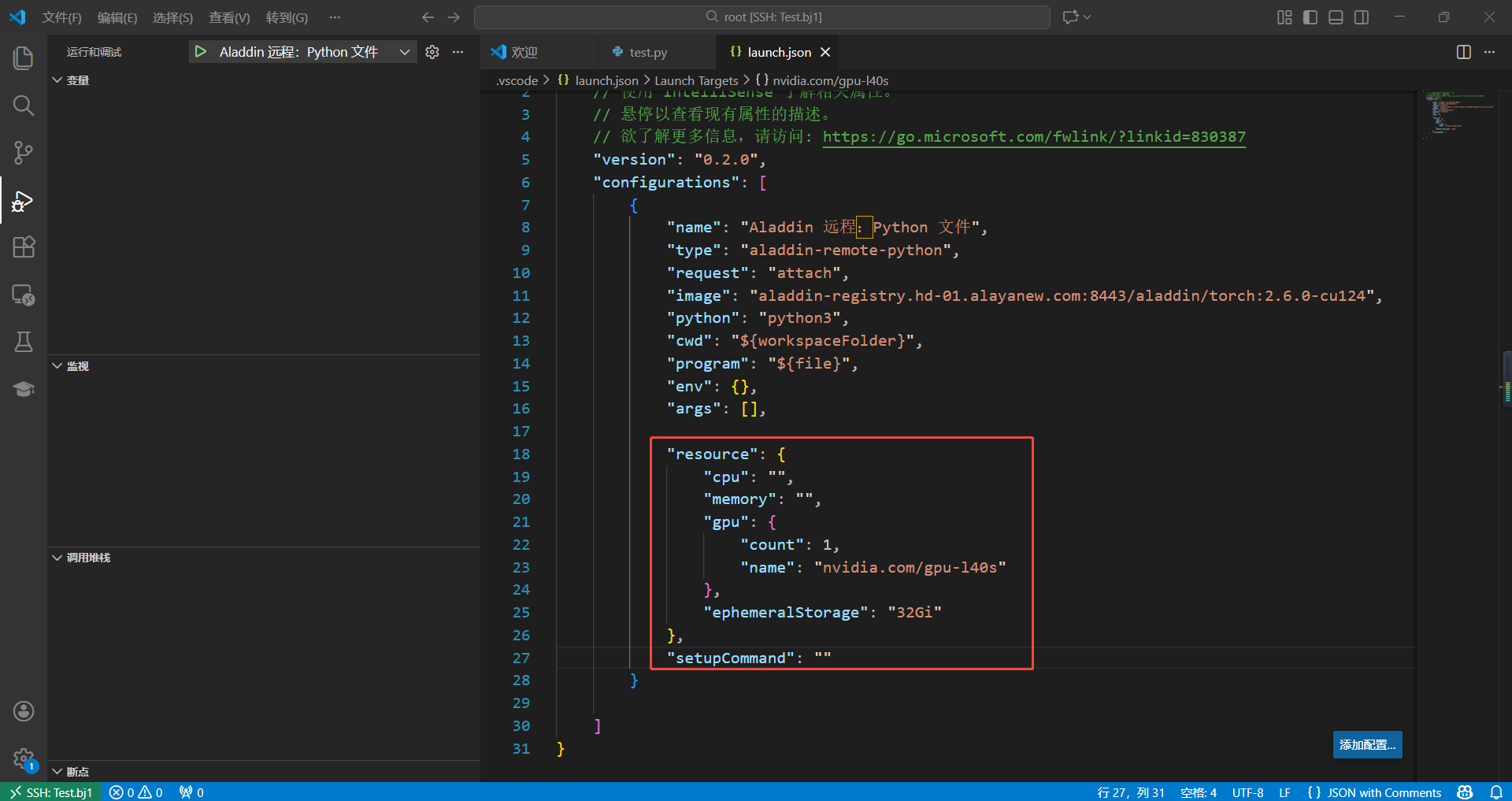
3.2 在launch.json文件中,选择“Aladdin 远程:Python 文件”选项,按照以下模板新增配置。
"resource": {
"cpu": "",
"memory": "",
"gpu": {
"count": 1,
"name": "nvidia.com/gpu-l40s"
},
"ephemeralStorage": "32Gi"
},
"setupCommand": ""
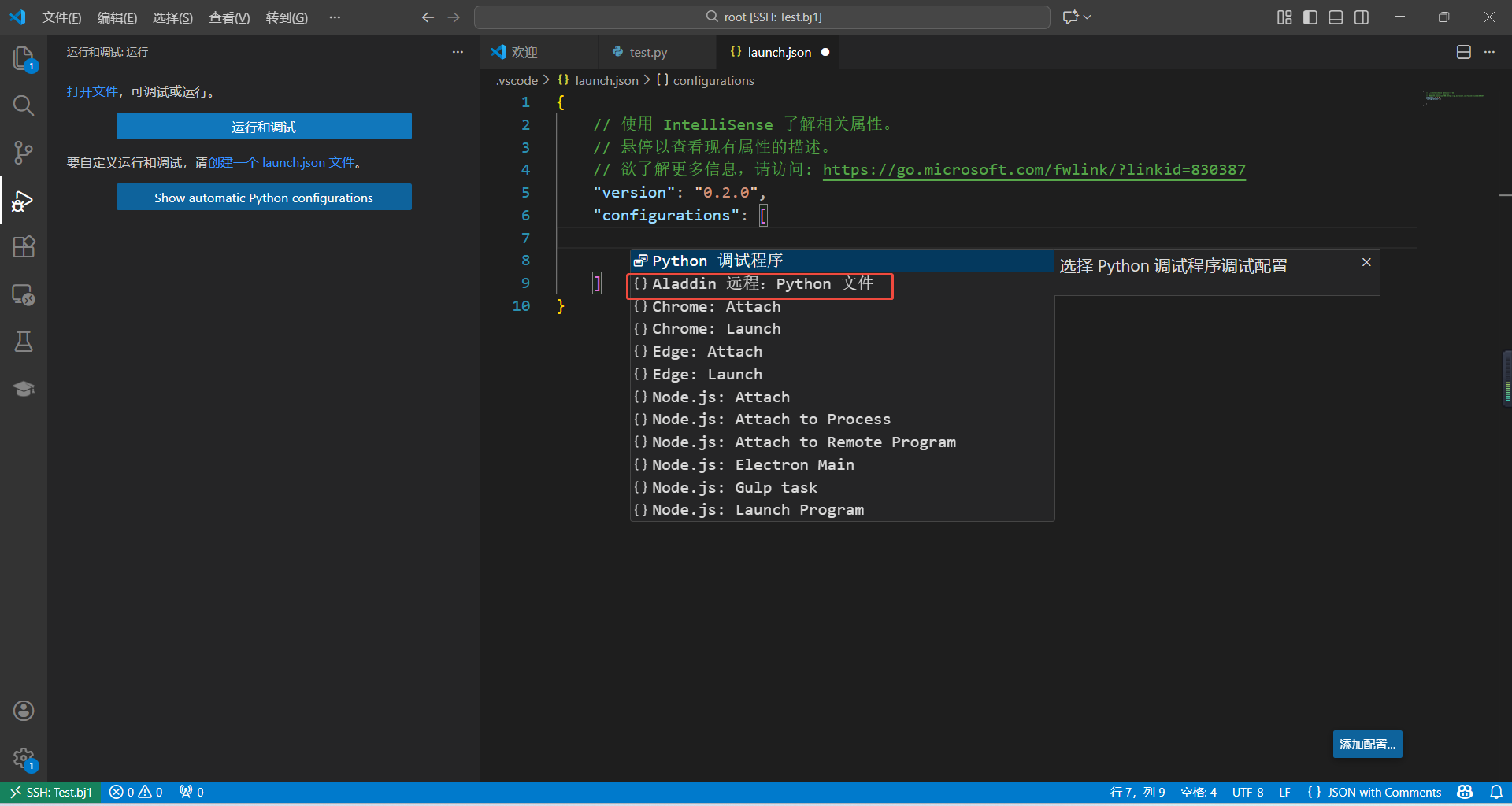 3.3 修改完成后,保存文件:
3.3 修改完成后,保存文件:
3.4 在test.py文件,选择“快速运行”即可完成上述GPU调用。
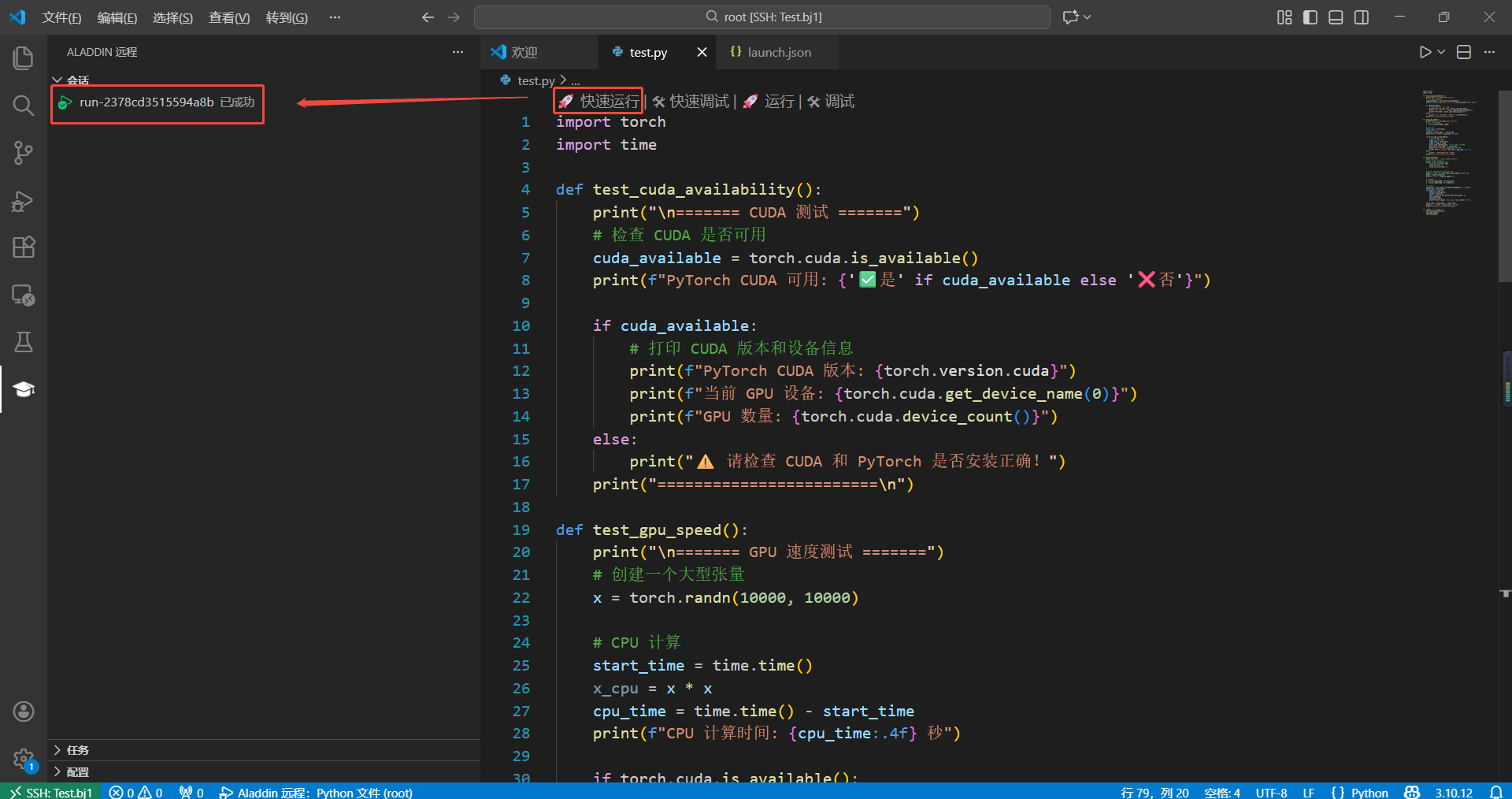
使用Conda环境运行Demo
强烈推荐按照本文说明,使用miniconda做环境配置。
- workshop启动成功后,进入远端页面,新建终端,在终端中安装miniconda,并确认安装在/root目录下:
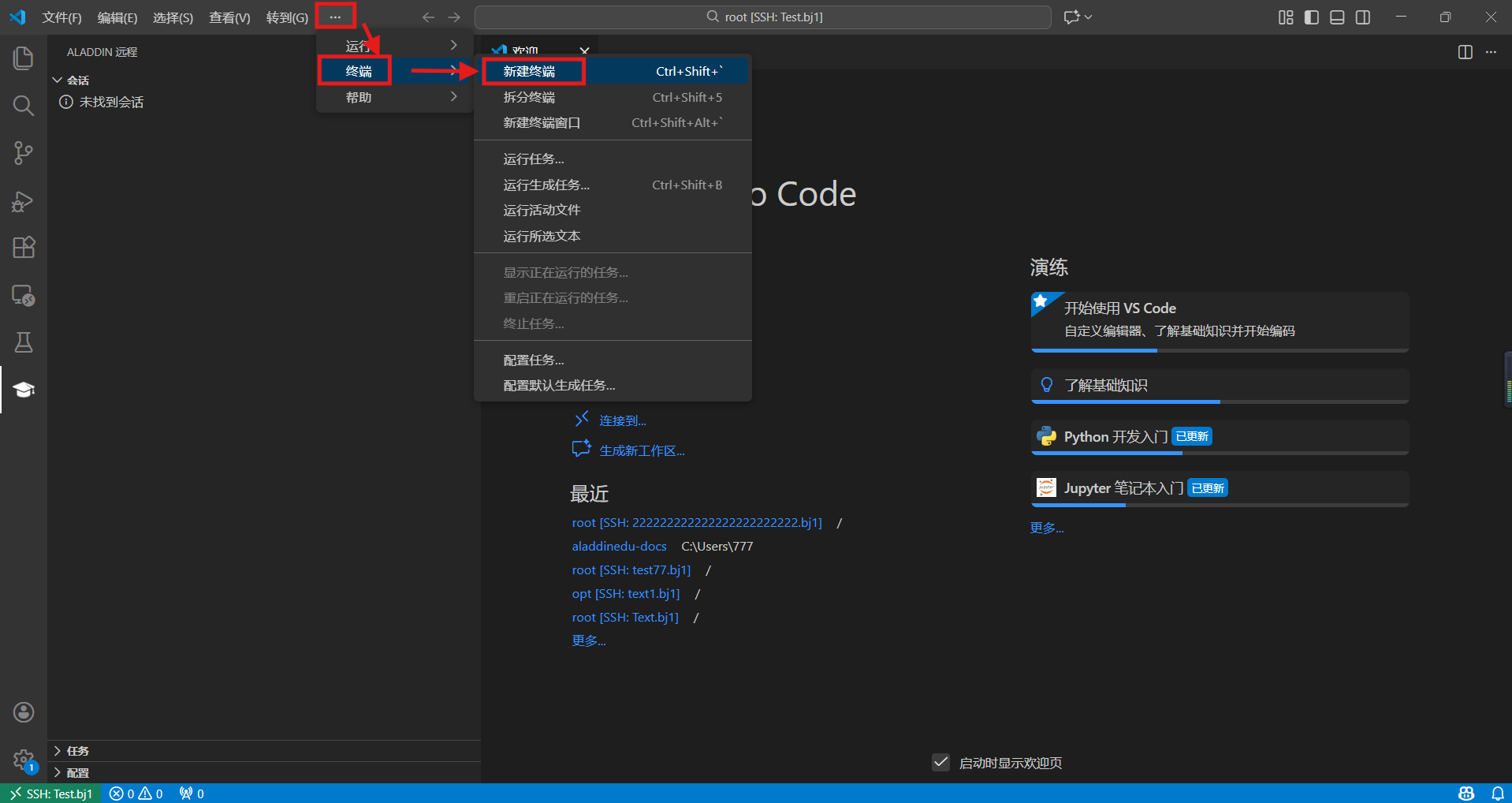
- Conda配置方法
# 下载最新版 Miniconda (Linux 64位)
curl -L -O https://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 运行安装脚本
bash Miniconda3-latest-Linux-x86_64.sh
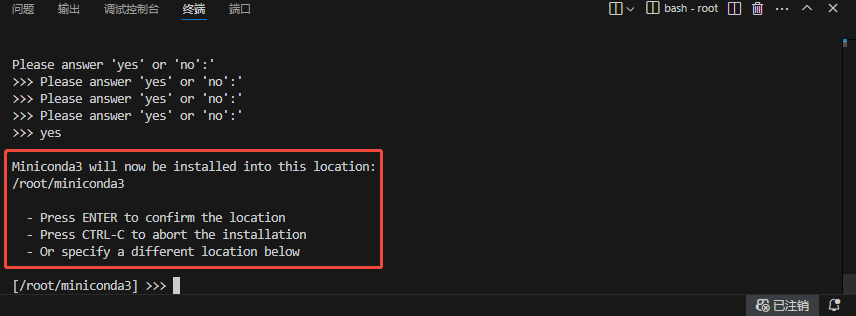
# 按 ENTER 确认默认安装路径 /root/miniconda3
# Note: You can undo this later by running `conda init --reverse $SHELL`
# 此项必须选择yes,安装完成后重启终端conda命令才能生效~
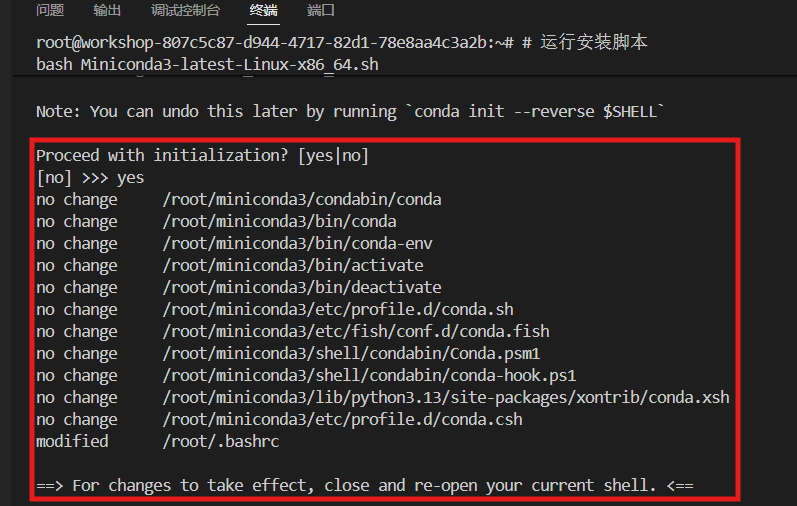
#关闭当前终端,重新启动一个新的终端
# 验证安装
conda --version
# 应该显示类似:conda 25.11.1
# 添加清华 conda 源
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
# 显示通道URL
conda config --set show_channel_urls yes
# 设置 pip 使用清华源
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
-
成功安装miniconda后,需配置python解释器——新建一个python文件,点击远端页面右下角的python版本号,切换到conda环境中的python: 或使用
Ctrl+Shift+P快捷键打开命令窗口,输入"Select Interpreter",更换python解释器。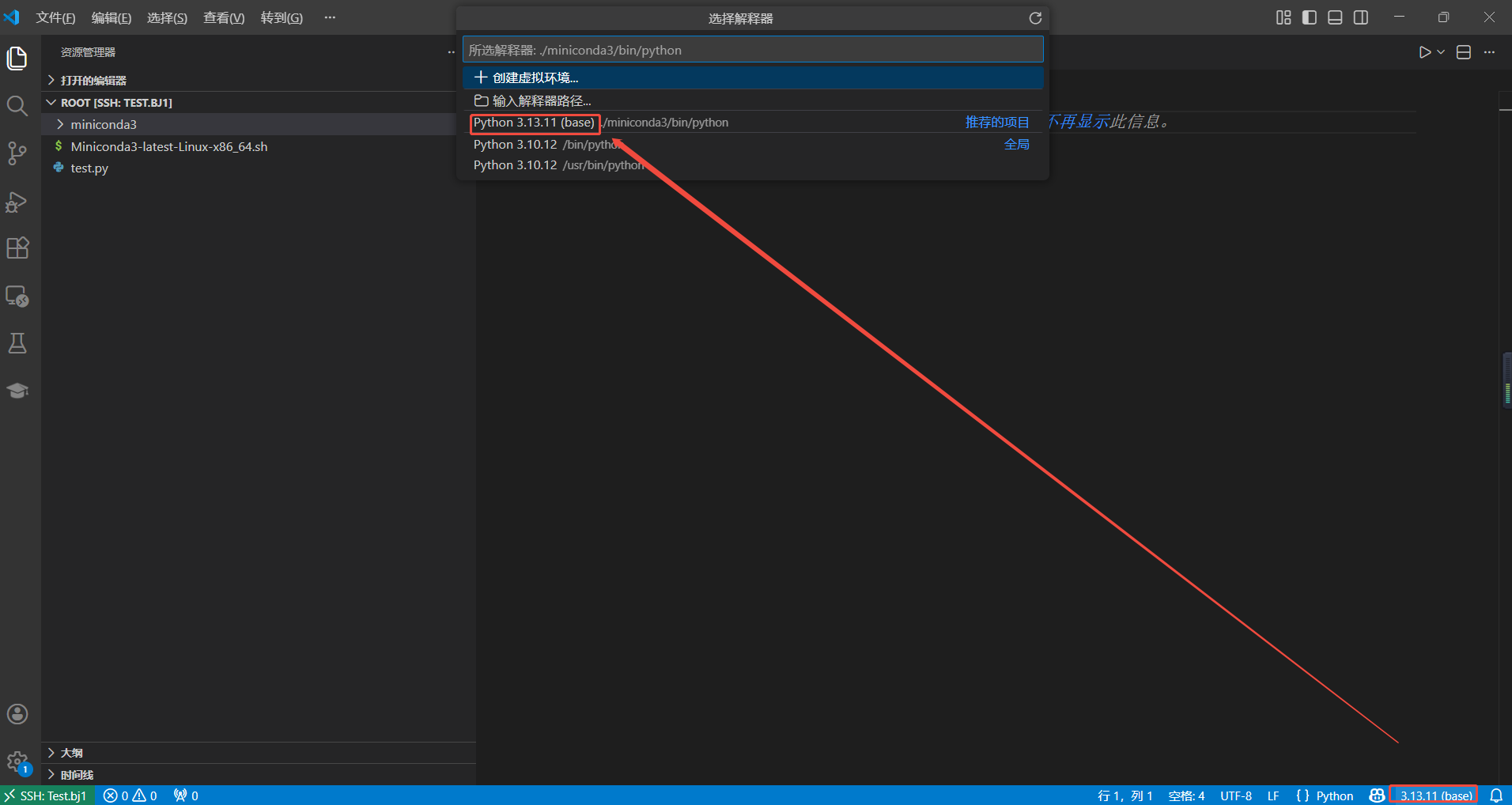
-
远端页面右下角的版本号出现conda环境名,环境切换成功:
-
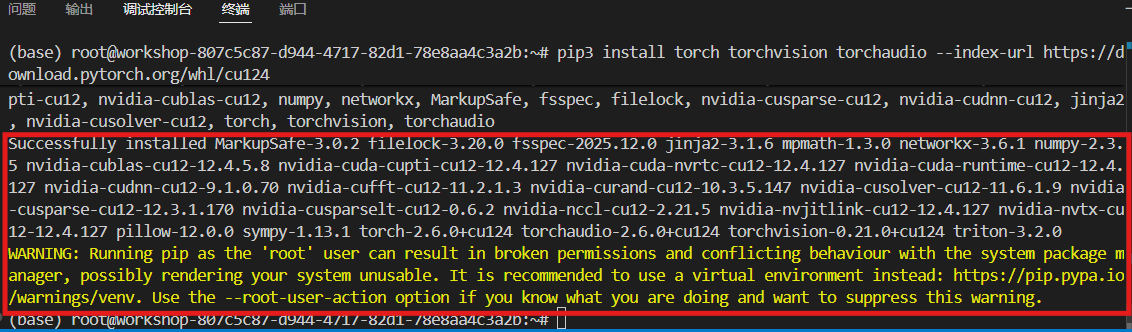
接着安装torch,推荐安装12.4版以适配GPU:
配置科学上网后将显著提升下载安装速度,具体步骤参考学术资源加速。
#安装cuda 12.4
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu124
- 使用下面代码测试cuda是否安装成功,以及是否与当前环境GPU兼容:
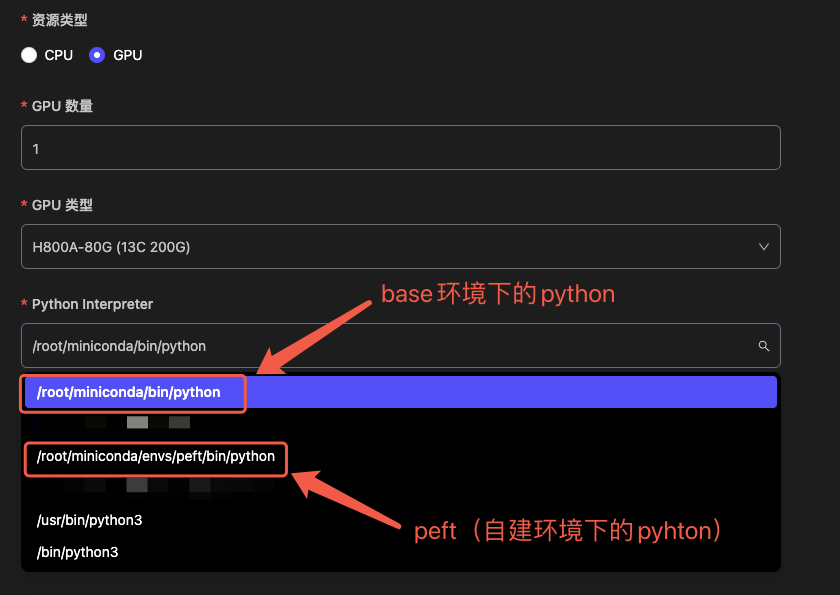
启动会话前,请检查 Python Interpreter 设置:
请务必选择 Miniconda 路径下 的解释器(base 或自建环境均可)。切勿选择 /usr/bin 下的系统自带 Python,以免环境配置失效。
import torch
import time
def test_cuda_availability():
print("\n======= CUDA 测试 =======")
# 检查 CUDA 是否可用
cuda_available = torch.cuda.is_available()
print(f"PyTorch CUDA 可用: {'✅是' if cuda_available else '❌否'}")
if cuda_available:
# 打印 CUDA 版本和设备信息
print(f"PyTorch CUDA 版本: {torch.version.cuda}")
print(f"当前 GPU 设备: {torch.cuda.get_device_name(0)}")
print(f"GPU 数量: {torch.cuda.device_count()}")
else:
print("⚠️ 请检查 CUDA 和 PyTorch 是否安装正确!")
print("========================\n")
def test_gpu_speed():
print("\n======= GPU 速度测试 =======")
# 创建一个大型张量
x = torch.randn(10000, 10000)
# CPU 计算
start_time = time.time()
x_cpu = x * x
cpu_time = time.time() - start_time
print(f"CPU 计算时间: {cpu_time:.4f} 秒")
if torch.cuda.is_available():
# 移动到 GPU 计算
x_gpu = x.to('cuda')
start_time = time.time()
x_gpu = x_gpu * x_gpu
torch.cuda.synchronize() # 确保 GPU 计算完成
gpu_time = time.time() - start_time
print(f"GPU 计算时间: {gpu_time:.4f} 秒")
print(f"GPU 比 CPU 快: {cpu_time / gpu_time:.1f} 倍")
else:
print("⚠️ GPU 不可用,跳过测试")
print("==========================\n")
def test_training():
print("\n======= 简单训练测试 =======")
# 定义一个极简神经网络
model = torch.nn.Sequential(
torch.nn.Linear(10, 100),
torch.nn.ReLU(),
torch.nn.Linear(100, 1)
)
# 如果有 GPU,将模型和数据移到 GPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = model.to(device)
print(f"使用设备: {device.upper()}")
# 模拟数据
X = torch.randn(1000, 10).to(device)
y = torch.randn(1000, 1).to(device)
# 训练循环
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
start_time = time.time()
for epoch in range(5):
optimizer.zero_grad()
output = model(X)
loss = torch.nn.functional.mse_loss(output, y)
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {loss.item():.4f}")
total_time = time.time() - start_time
print(f"总训练时间: {total_time:.2f} 秒")
print("==========================\n")
if __name__ == "__main__":
test_cuda_availability()
test_gpu_speed()
test_training()