使用SSH快速连接(邪修)
本节预计完成时间:5min
本节将会介绍如何通过SSH连接workshop,完成GPU调用。
❗️注意:此方法启动的workshop启动完成即对GPU计费,必须手动停止workshop后才会停止计费。当然停止workshop后您在workshop中运行的训练任务也会同时终止。
使用GPU启动workshop
-
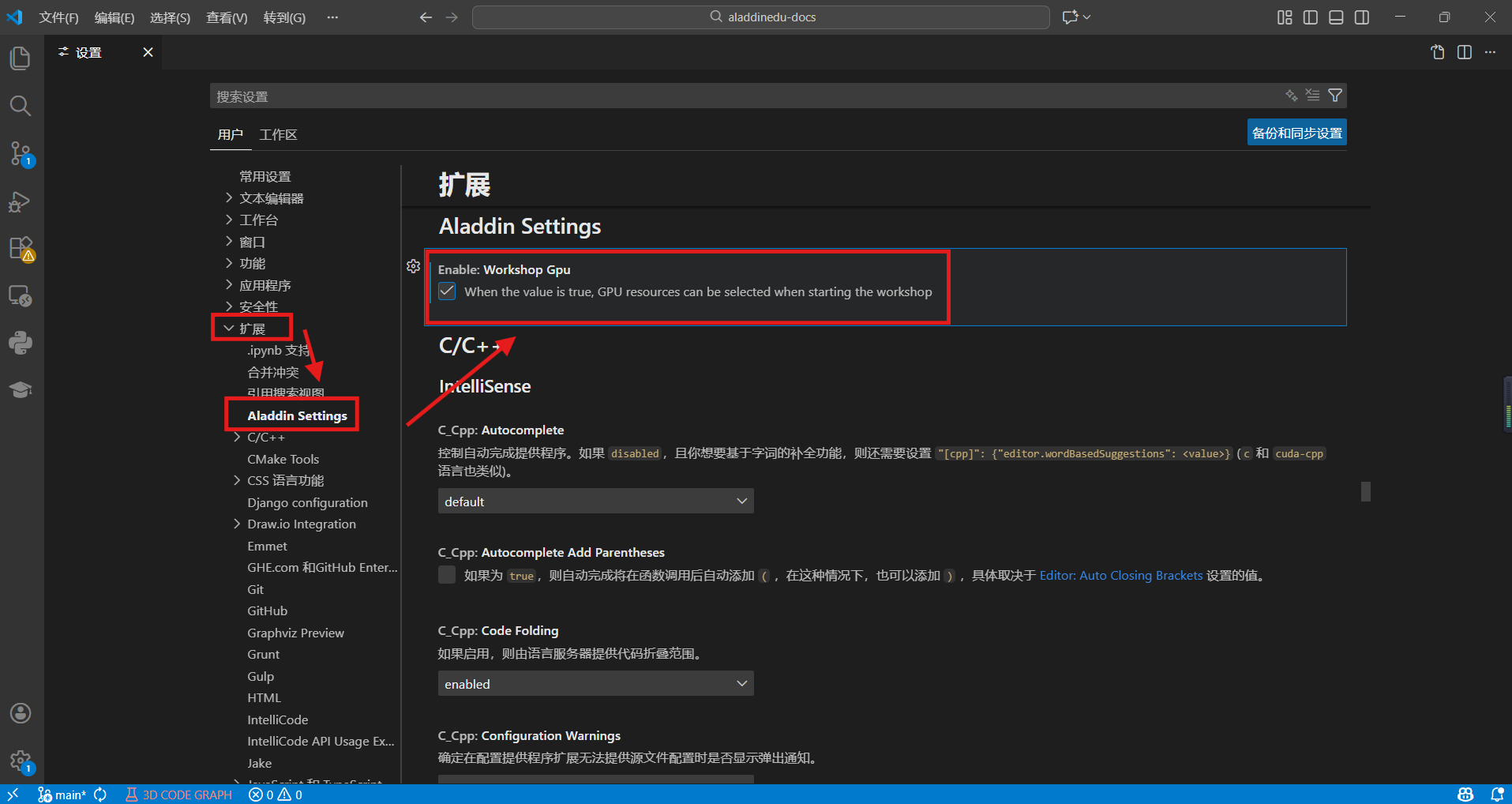
在VSCode上选择左下角的“管理”图标,选择“设置”,在设置中找到扩展下的Aladdin Settings,勾选workshop GPU。
-
在AladdinEdu插件里创建工作台,资源类型选择GPU,选择您需要调用的GPU数量与卡型,完成workshop的创建,等待创建成功后可直接关闭新弹出的窗口。
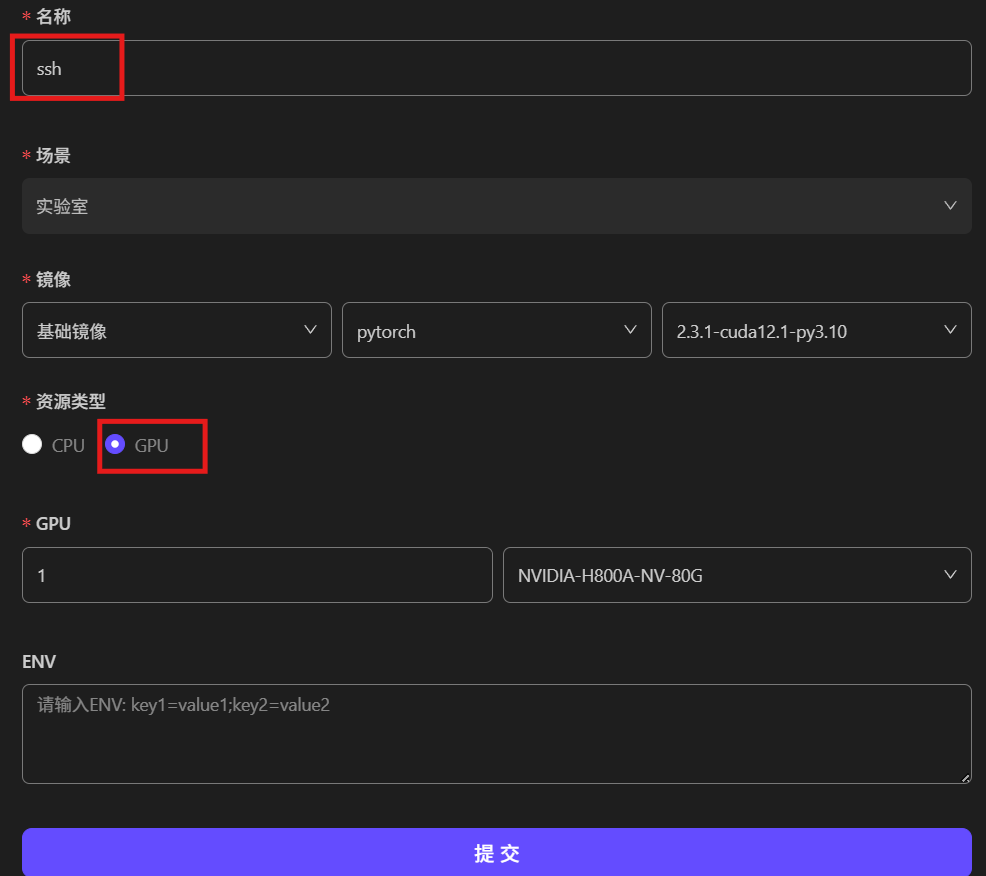
❗️注意:再次提醒,按此方法启动的workshop将会在启动完成即对GPU计费,必须手动停止workshop后才会停止计费。
获取SSH连接命令
点击“复制SSH连接”按钮,复制已经创建好的SSH连接指令。
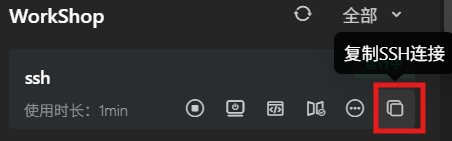
注:目前采用的是本地私钥连接,即在您更换设备后,需要重新点击按钮获取新指令。
通过SSH运行Demo
本案例将使用Xterminal演示Demo的运行,MAC用户也可以使用自带终端进行连接。
-
在新终端中粘贴ssh连接命令,回车:
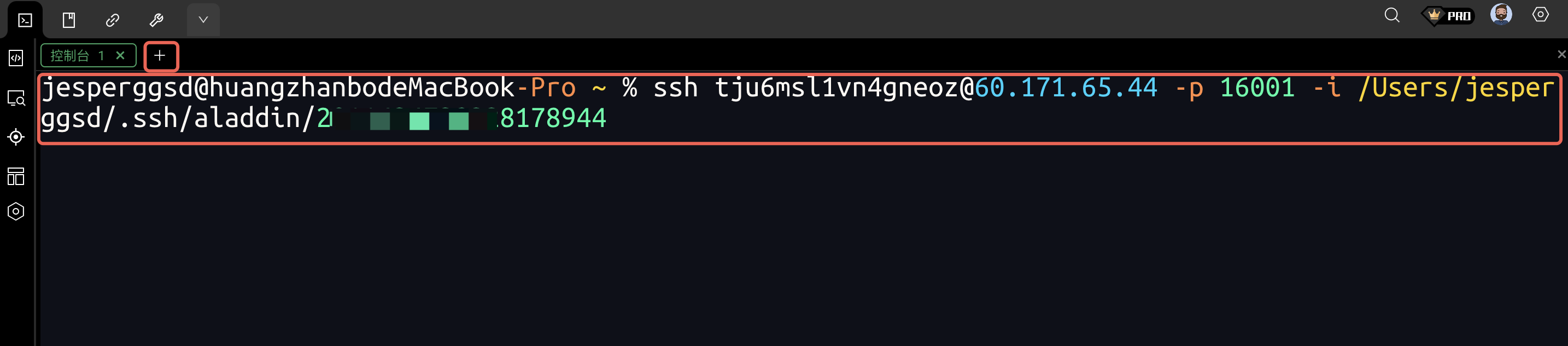
-
连接成功如下图所示,红框内为您连接workshop的id:
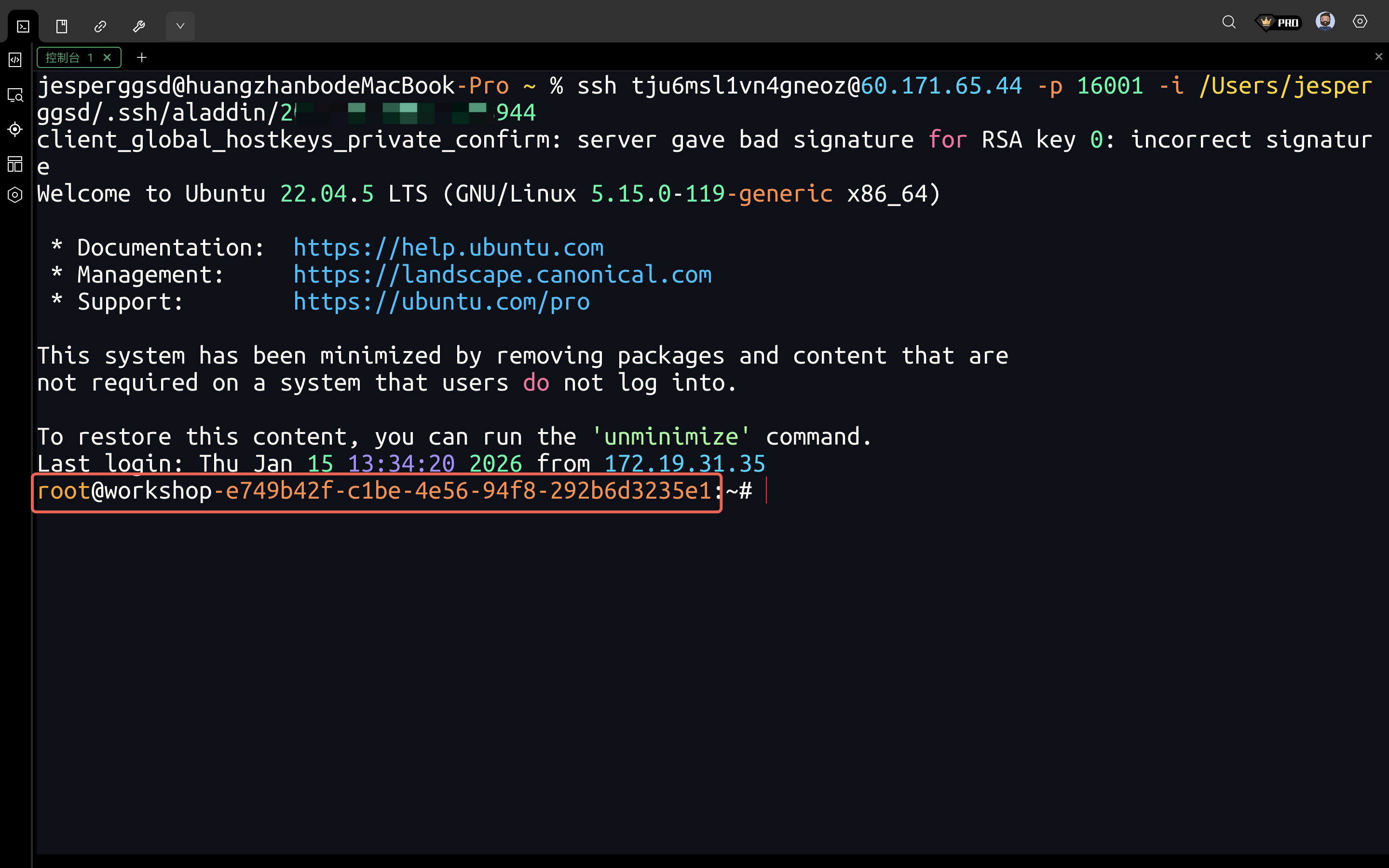
-
使用以下测试代码新建测试文件:
import torch
import time
def test_cuda_availability():
print("\n======= CUDA 测试 =======")
# 检查 CUDA 是否可用
cuda_available = torch.cuda.is_available()
print(f"PyTorch CUDA 可用: {'✅是' if cuda_available else '❌否'}")
if cuda_available:
# 打印 CUDA 版本和设备信息
print(f"PyTorch CUDA 版本: {torch.version.cuda}")
print(f"当前 GPU 设备: {torch.cuda.get_device_name(0)}")
print(f"GPU 数量: {torch.cuda.device_count()}")
else:
print("⚠️ 请检查 CUDA 和 PyTorch 是否安装正确!")
print("========================\n")
def test_gpu_speed():
print("\n======= GPU 速度测试 =======")
# 创建一个大型张量
x = torch.randn(10000, 10000)
# CPU 计算
start_time = time.time()
x_cpu = x * x
cpu_time = time.time() - start_time
print(f"CPU 计算时间: {cpu_time:.4f} 秒")
if torch.cuda.is_available():
# 移动到 GPU 计算
x_gpu = x.to('cuda')
start_time = time.time()
x_gpu = x_gpu * x_gpu
torch.cuda.synchronize() # 确保 GPU 计算完成
gpu_time = time.time() - start_time
print(f"GPU 计算时间: {gpu_time:.4f} 秒")
print(f"GPU 比 CPU 快: {cpu_time / gpu_time:.1f} 倍")
else:
print("⚠️ GPU 不可用,跳过测试")
print("==========================\n")
def test_training():
print("\n======= 简单训练测试 =======")
# 定义一个极简神经网络
model = torch.nn.Sequential(
torch.nn.Linear(10, 100),
torch.nn.ReLU(),
torch.nn.Linear(100, 1)
)
# 如果有 GPU,将模型和数据移到 GPU
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = model.to(device)
print(f"使用设备: {device.upper()}")
# 模拟数据
X = torch.randn(1000, 10).to(device)
y = torch.randn(1000, 1).to(device)
# 训练循环
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
start_time = time.time()
for epoch in range(5):
optimizer.zero_grad()
output = model(X)
loss = torch.nn.functional.mse_loss(output, y)
loss.backward()
optimizer.step()
print(f"Epoch {epoch + 1}, Loss: {loss.item():.4f}")
total_time = time.time() - start_time
print(f"总训练时间: {total_time:.2f} 秒")
print("==========================\n")
if __name__ == "__main__":
test_cuda_availability()
test_gpu_speed()
test_training()
-
使用python命令运行Demo,查看输出:
-
使用完成后,一定要关闭workshop,才会停止计费: